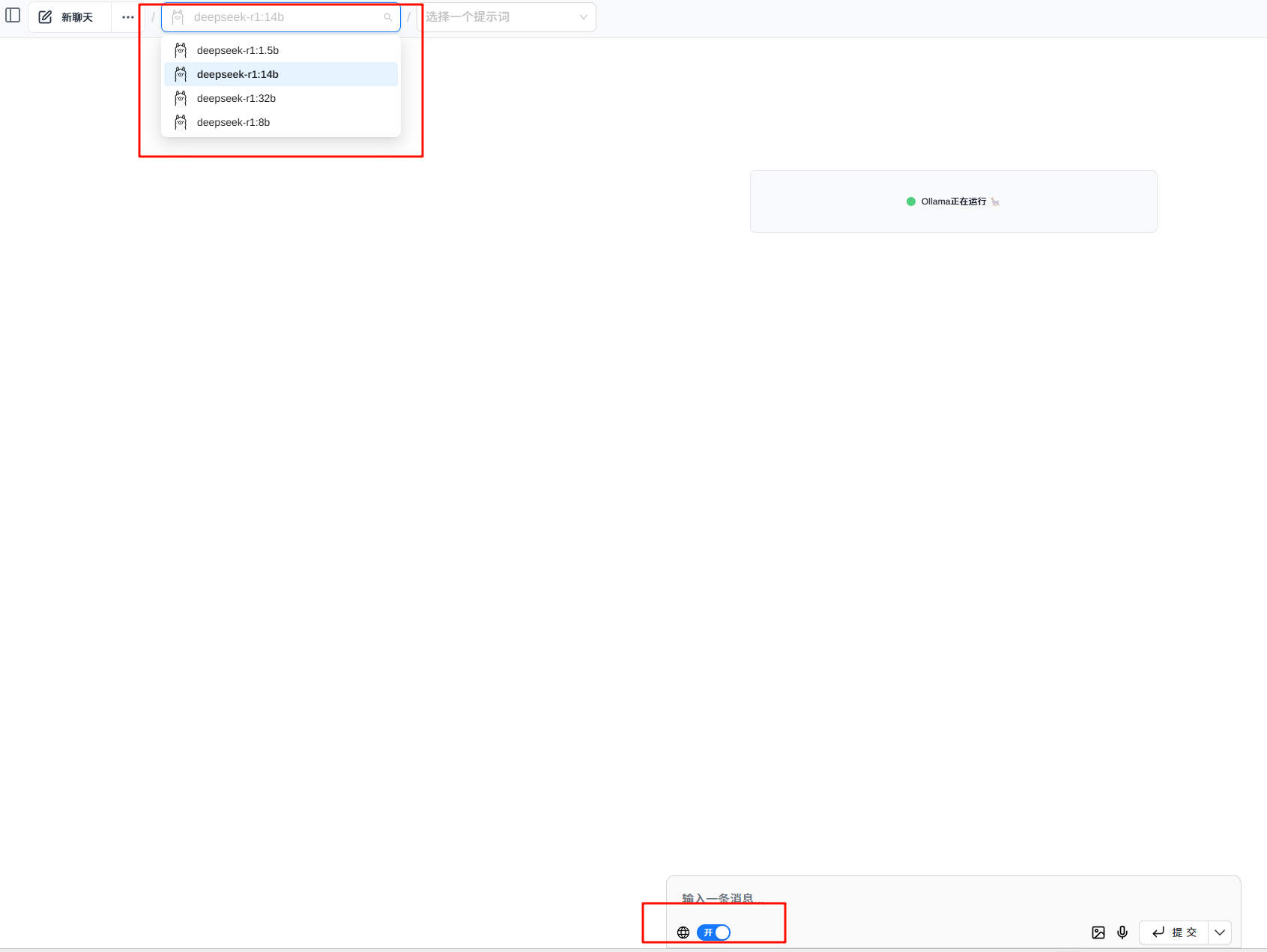
DeepSeek R1本地化部署+web端访问+LLM交互平台
前言
针对DeepSeek高频次服务繁忙问题,本地化部署已成为用户实现稳定、高效AI交互的主流方案。通过本地部署,用户可在终端设备上构建私有化知识库系统,实现离线运行、数据隐私保护、低延迟响应等核心需求
本文将详细介绍如何基于DeepSeek R1+Ollama+Cherry Studio+Page Assist实现本地化部署,帮助您轻松搭建并使用DeepSeek服务。通过Web UI界面,您可以直接与模型进行交互式对话;同时,借助功能强大的交互平台架构,打造属于自己的专属AI聊天室变得轻而易举。
一、基础环境搭建
Ollama 是一个可以在本地轻松部署开源大语言模型(LLM)的工具框架,它允许开发者在本地环境中方便地运行和测试不同的语言模型,如 DeepSeek、Llama等。
官网地址:https://ollama.com/
github地址:https://github.com/ollama/ollama
访问Ollama官网下载对应操作系统的安装包(Windows/macOS/Linux),完成一键安装
我这里以windows为例:

下载完成后进行安装:
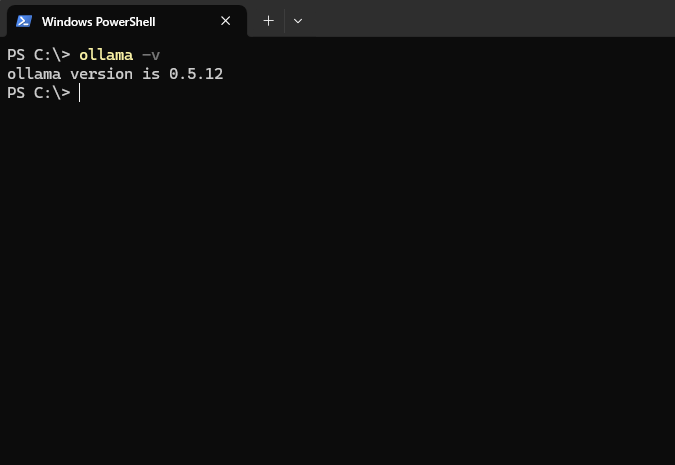
安装验证
安装完成后,在powershell中输入ollama -v,如果显示版本号即安装成功
各型号特性与硬件需求如下:
| 型号 | CPU | 内存 | 显卡(显存要求) | 存储 | 适用场景 | 成本参考 |
|---|---|---|---|---|---|---|
| 1.5B | 4核(Intel i5/Ryzen 5) | ≥8GB | 核显或低端独显(≥4GB) | ≥20GB SSD | 简单文本生成、轻量开发 | 个人级(2k-5k) |
| 7B | 8核(i7/Ryzen 7) | ≥16GB | 中端独显(RTX 3060,≥8GB) | ≥50GB NVMe | 代码生成、数据分析 | 入门级(5k-1.5w) |
| 8B | 8核(i7/Ryzen 7) | ≥16GB | 中高端独显(RTX 4060,≥10GB) | ≥50GB NVMe | 逻辑推理、轻量高精度任务 | 进阶级(1w-3w) |
| 14B | 12核(i9/Ryzen 9) | ≥32GB | 高端独显(RTX 4090,≥16GB) | ≥100GB NVMe | 复杂任务(合同分析、长文本) | 企业级(3w-8w) |
| 32B | 16核(服务器级) | ≥64GB | 专业卡(A100 40GB) | ≥200GB NVMe | 多模态处理、专业领域咨询 | 高性能级(8w-15w) |
| 70B | 32核(双路Xeon/EPYC) | ≥128GB | 多卡集群(2x A100/H100) | ≥500GB NVMe | 科研级推理、大规模生成 | 科研级(15w-50w) |
| 671B | 多节点服务器 | ≥512GB ECC | 分布式GPU集群(8x H100) | ≥1TB NVMe | 超大规模训练、AGI探索 | 顶尖级(50w+) |
根据选择好的模型进行拉取,详情可见ollama官网Models中的deepseek-r1,命令如下:
DeepSeek-R1-Distill-Qwen-1.5B
1 | ollama run deepseek-r1:1.5b |
DeepSeek-R1-Distill-Qwen-7B
1 | ollama run deepseek-r1:7b |
DeepSeek-R1-Distill-Llama-8B
1 | ollama run deepseek-r1:8b |
DeepSeek-R1-Distill-Qwen-14B
1 | ollama run deepseek-r1:14b |
DeepSeek-R1-Distill-Qwen-32B
1 | ollama run deepseek-r1:32b |
DeepSeek-R1-Distill-Llama-70B
1 | ollama run deepseek-r1:70b |
若出现success,则拉取完成,会自动启用该模型。如下图:

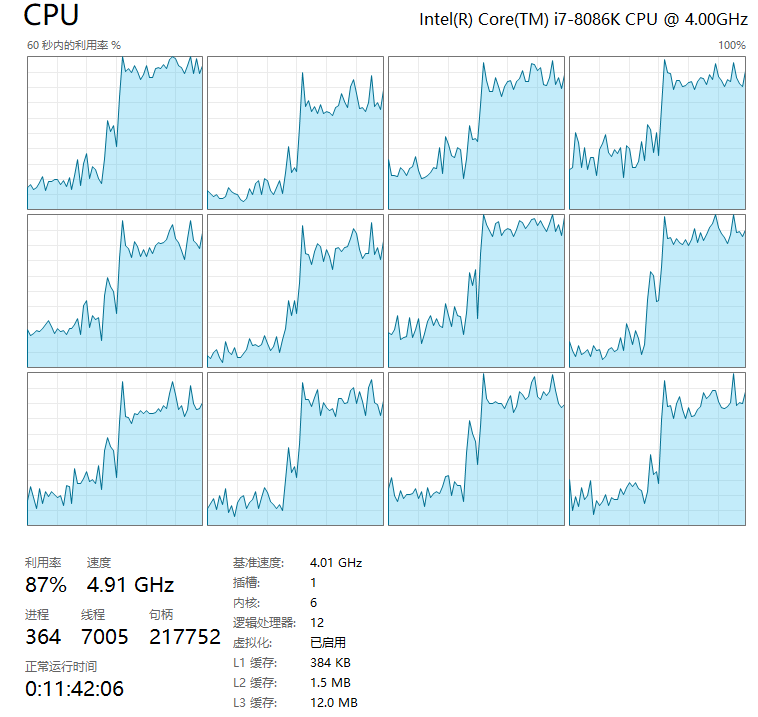
博主的配置是4080ti显卡,32G内存,i7 8086k CPU,使用的是deepseek-r1:14b,思考速度大约15s左右,CPU使用率80%左右,内存使用率40%,GPU 使用率54%,显存使用率92%。ollama全部加载在GPU中。可供各位小伙伴选择模型时参考。
CPU使用率:
GPU使用率:
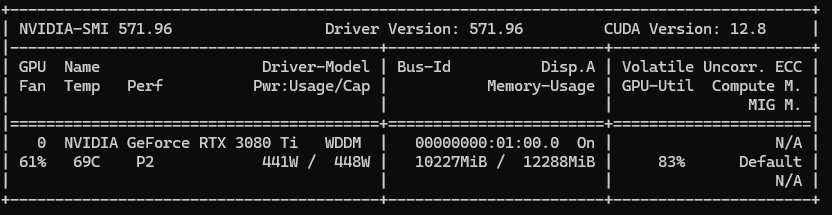
ollama完全使用GPU:

在升级至DeepSeek-R1:32B这类专业级模型时,需配置显存更高且专业的显卡,由于模型参数量达320亿级别,显存不足会导致用户界面响应会出现明显卡顿,系统将自动调用大量系统内存进行补偿,单次任务处理时长普遍超过200秒。
各个版本占用的空间如下:

二、打造专属DeepSeek
前往Cherry Studio 官方网站,根据你的操作系统下载安装。
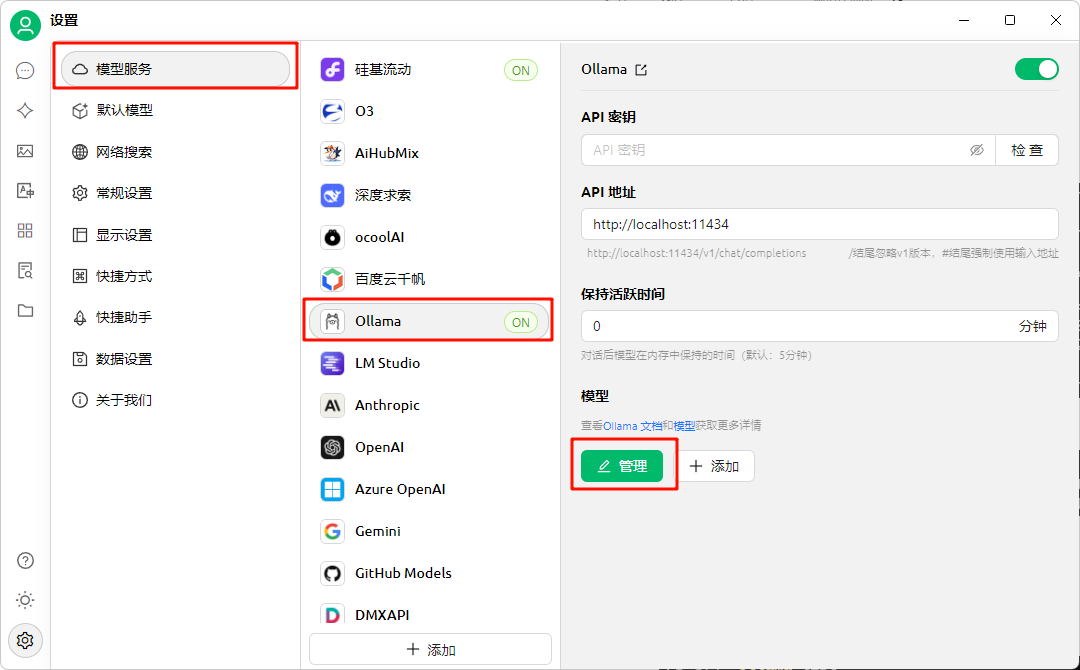
打开 Cherry Studio,在设置中找到模型服务
- 从模型列表中的Ollama选择与你本地部署的 DeepSeek-R1 模型版本对应的选项
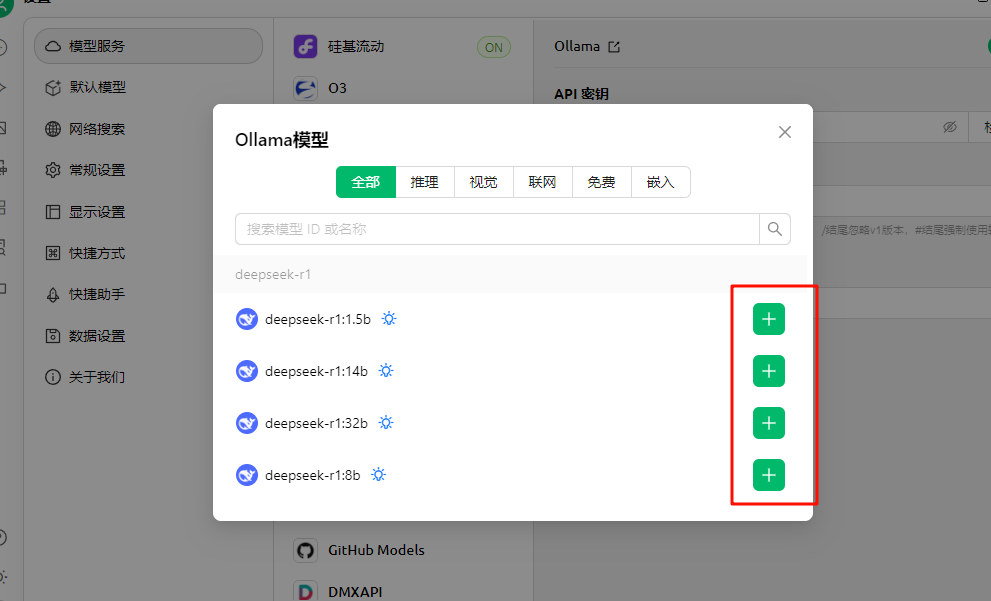
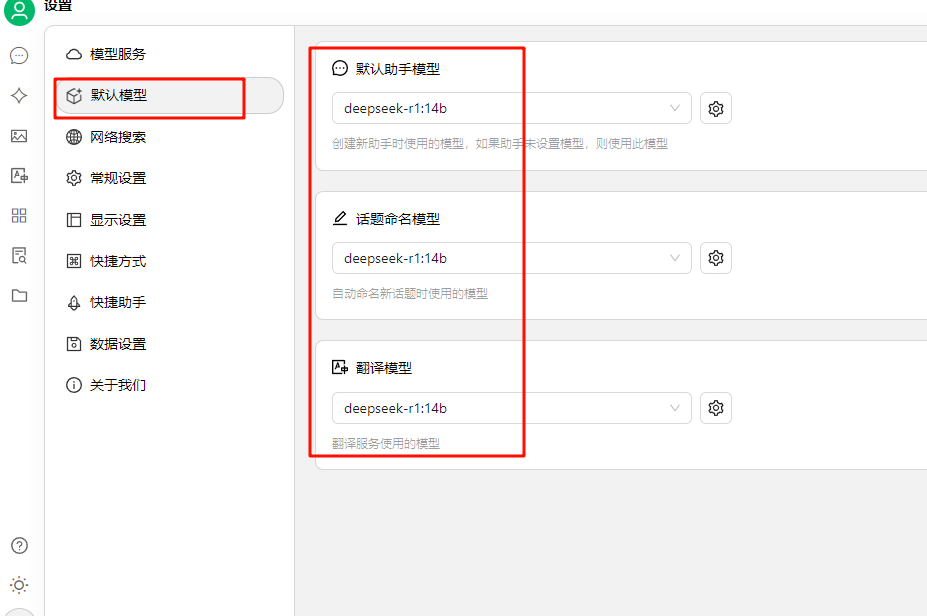
默认模型中选择本地部署对应的模型
目前新版的Cherry Studio已支持网络搜索,在网络搜索中可以注册Tavily并设置api秘钥,注册账号可以用github或google
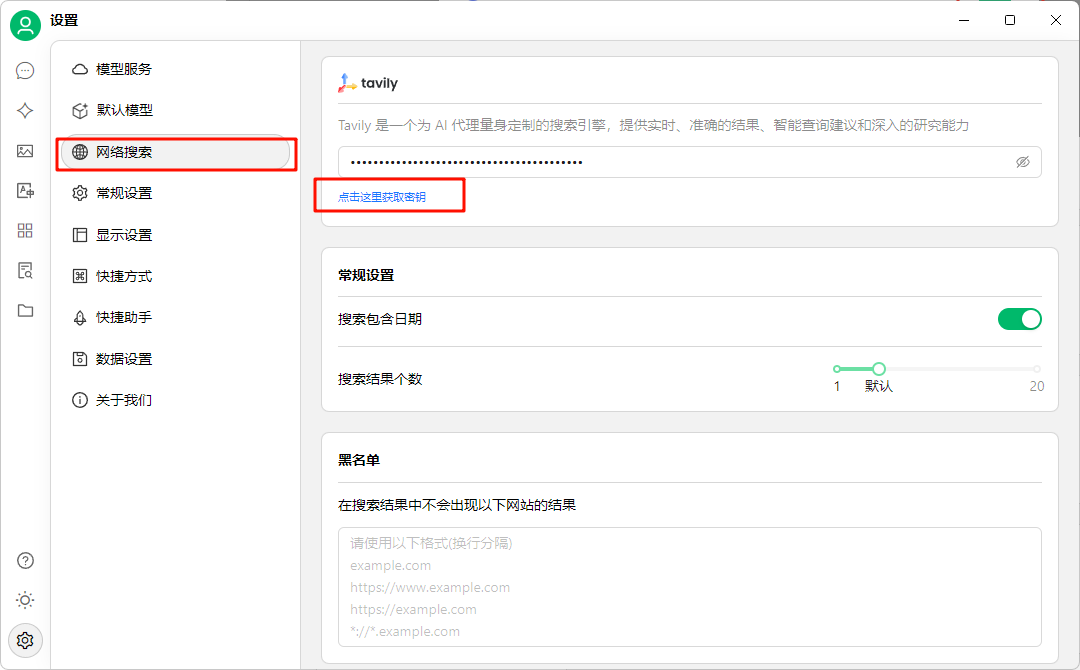
配置到这里就可以开始使用专属自己的DeepSeek了,如需使用网络搜索,可在助手页面点开“开启网络搜索”。智能体内也有一些预设的提示词可供食用。
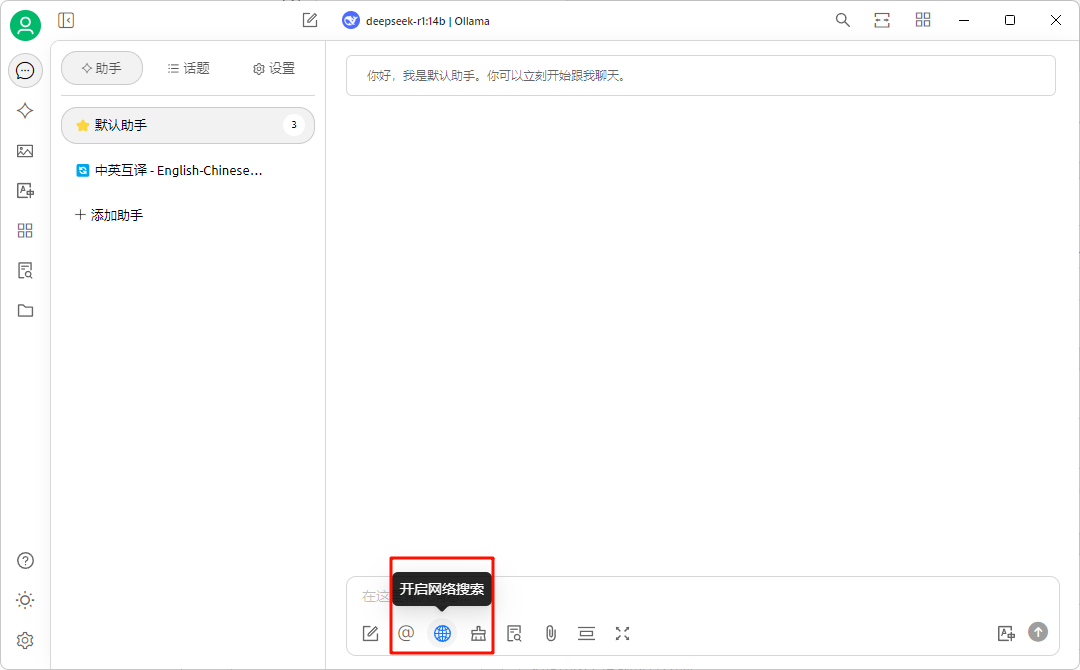
三、配置使用Web UI
Page Assist 是一款开源浏览器扩展程序,主要用于提升用户在网页浏览过程中与本地 AI 模型的交互效率,提供类似 ChatGPT 的 Web UI 界面,且支持用户与本地运行的 AI 模型(如 Ollama、Gemini Nano、DeepSeek 等)进行多轮对话。
Github 官网:https://github.com/n4ze3m/page-assist
首先打开Chrome浏览器,进入应用商店,搜索Page Assist,点击添加至Chrome:
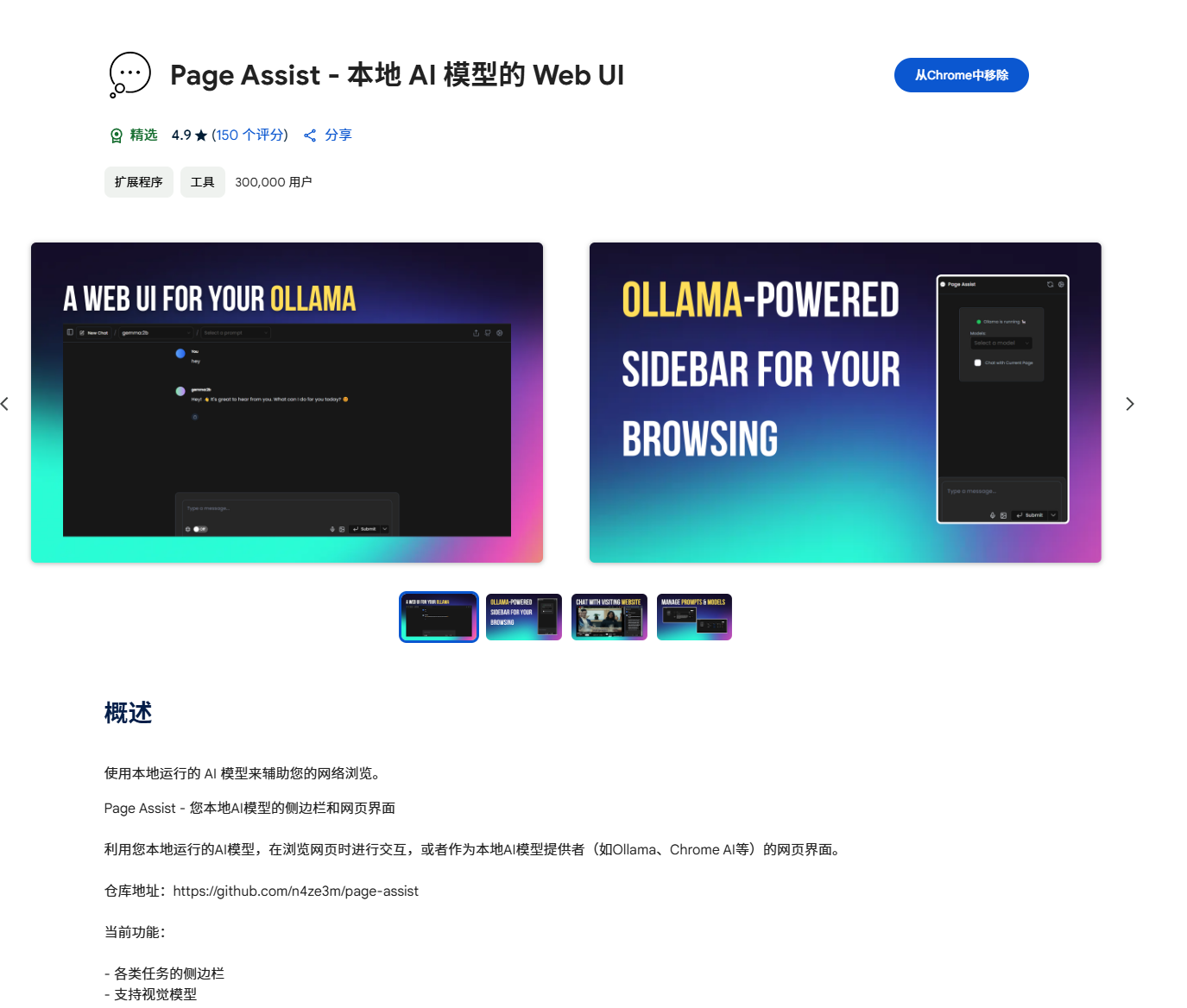
添加后在浏览器右上角的扩展程序图标中打开它即可看到Web UI界面了:
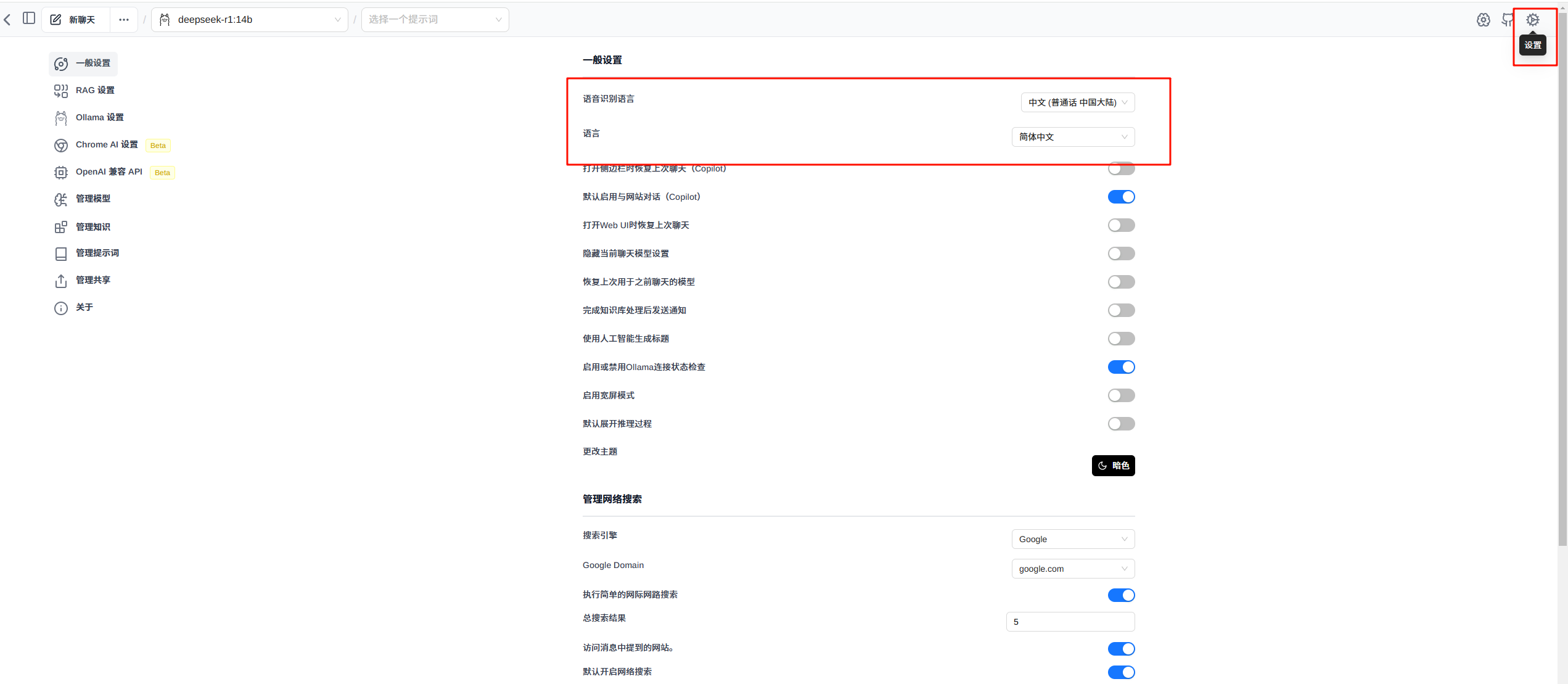
点击右上角设置,可以修改语音识别语言和界面显示语言:
选择好本地搭建好的模型后即开始使用,并且可以开启搜索网络。